Introduction
Although new to the Enterprise Library, Semantic logging is not a new concept. It has been adopted for years under different names such as "structured logging", "strongly typed logging" and "schematised logging" to name a few.
What is it?
SLAB inherits event structure from the Event Tracing for Windows (ETW) pipeline, allowing it to store the payload of the event along with it's metadata. In this case you have data along with data which describes the format. ETW has built in support for logging a stack trace along with the event and can also be extended which enables you to add your own event data.SLAB's secret source is to make light work of using a reliable and robust logging infrastructure that has been around since Windows 2000 in a way that abstracts us as developers from the messy details of manifests and publishing to ETW, which is typically overly complex, focusing on What you want to log and Where you want to store those logs.
What you want to log
- The parameters the log method expects
- The Logging Level
- The Event Id
- The Task (optional)
- Operational Codes (optional)
At Assemblysoft we specialise in Custom Software Development tailored to your requirements. We have experience creating Booking solutions, as we did for HappyCamperVan Hire. You can read more here.
We can onboard and add value to your business rapidly. We are an experienced Full-stack development team able to provide specific technical expertise or manage your project requirements end to end. We specialise in the Microsoft cloud and .NET Solutions and Services. Our developers are Microsoft Certified. We have real-world experience developing .NET applications and Azure Services for a large array of business domains. If you would like some assistance with Azure | Azure DevOps Services | Blazor Development or in need of custom software development, from an experienced development team in the United Kingdom, then please get in touch, we would love to add immediate value to your business.

Assemblysoft - Your Safe Pair of Hands
Where you want to log
- Console
- Flat File
- Rolling File
- Sql Database
- Windows Azure Table
In-Process
When using the SLAB in-process, all configuration is performed in code. You first create an ObservableListener<EventEntry> (default) and you subscribe to the listener with one or more event sinks.Out-of-Process
Sample Code
Road Map
At this time i envisage at least 3 parts consisting of:- Part 1 - Semantic Logging Application Block - Microsoft Enterprise Library 6 (In Process)
- Part 2 - Semantic Logging in Windows Azure (Out of Process)
- Part 3 - Extending Semantic Logging - Creating Custom Sinks for Windows Azure
Additional Reading - What is the Enterprise Library?
If you have used other blocks from the Enterprise Library before, feel free to skip this section. "Enterprise Library is made up of a series of application blocks, each aimed at managing specific crosscutting concerns. In case this concept is unfamiliar, crosscutting concerns are those annoying tasks that you need to accomplish in several places in your application. When trying to manage crosscutting concerns there is often the risk that you will implement slightly different solutions for each task at each location in your application, or that you will just forget them altogether. Writing entries to a system log file or Windows Event Log, and validating user input are typical crosscutting concerns. While there are several approaches to managing them, the Enterprise Library application blocks make it a whole lot easier by providing generic and configurable functionality that you can centralise and manage. What are application blocks? The definition we use is "pluggable and reusable software components designed to assist developers with common enterprise development challenges." Application blocks help address the kinds of problems developers commonly face from one line-of-business project to the next. Their design encapsulates the Microsoft recommended practices for Microsoft .NET Framework-based applications, and developers can add them to .NET-based applications and configure them quickly and easily." - Direct quote: Enterprise Library Developers Guide.The diagram below taken from the Enterprise Library Developers Guide (preview) shows the different blocks, their dependencies and the highlighted block we will be focusing on
Figure 1

Why another Logging Framework?
There a lot of similarities in terms of the features and the things you can do when compared to other frameworks including logging events to multiple destinations, filtering and formatting. The real power of Semantic Logging comes from the way SLAB events get written to the logs. Your events are strongly typed which allows for a consistent format and structure. There is no chance of a developer making a coding error when the log event is written such as passing in the wrong event id or verbosity. It is easier to post analyse and query the log results due to their strongly types nature and formatting. It becomes easier to consume log data from other applications. You can more easily see the big picture in terms of correlation between business processes. Automation can take place in a much cleaner way as the sinks available can utilise database and cloud storage mechanisms, preserving the actual state, already in use and being actively consumed by existing applications.
Responsibility of concerns
Rich Data - keeping the context
Putting some meat on the bone (What do i need to do as a dev)
Get References


Designing an EventSource (The What)
- String
- int32
- int64
- Guid
- Long

Logging an Event

Consuming events (The where)
As mentioned earlier, there are a number of sinks available out of the box.
- Console
- Flat File
- Rolling Flat File
- Sql Database Sink
- Windows Azure Table Sink
For our first sample we will use the Console Sink. But first we need to create a listener as shown below:
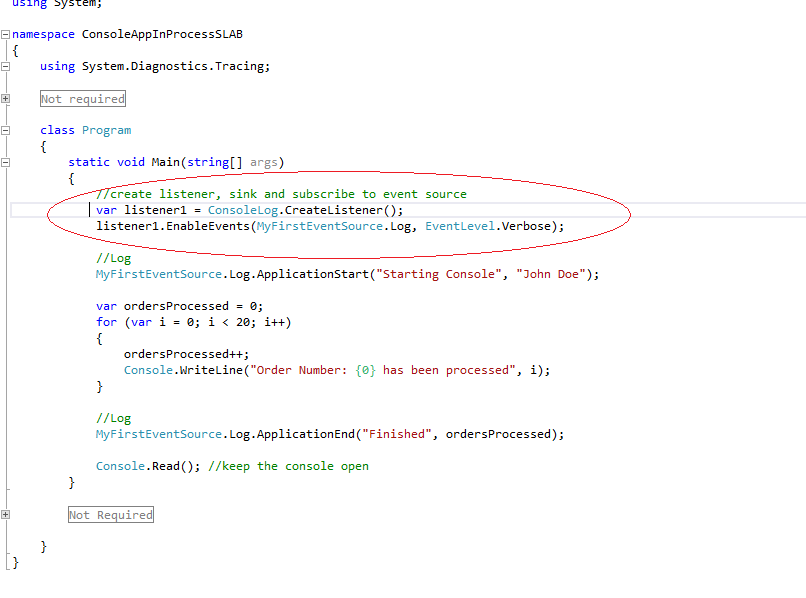
Simple Output
The Console output can be seen below:

Adding another listener
Next we add another listener, this time making use of the out of the box 'FlatFile' sink. As shown below, with just two lines of code, our logs are being stored in a text file 'Log.txt'


Formatting the results
One nice feature of the sinks is the ability to add a formatter. This will be quite attractive to those wanting to migrate from existing logging frameworks to Semantic Looging but still want to retain the current log format so that post analysis can continue without interuption after moving to SLAB. There are a number of formatters available out of the box for example a Json formatter.
To show how simple it is to add a formatter, we have added a simple Console Mapper which changes the color of the console based on the Event Level.
First we add an Event Level to the Event Source [Event] attribute as shown below:

Now the design of the Event Source has been updated, the color mapper is added as shown:

With very little effort, we have formatted our output in a way that adds real value. The results when running the console, which uses the formatter, are shown once more below:

Source Code
References (recommended reading)
- Enterprise Library Developers Guide (preview)
- Enterprise Library 6 - Source Code
- Embracing Semantic Logging - Grigori Melnik MSFT
- Channel9.msdn PerfView Tutorial - Generating Your Own Events with EventSources